

探索未来:优秀开源 AI 自然语言模型推荐
在人工智能的浪潮中,自然语言处理(NLP)技术正以前所未有的速度发展。开源 AI 自然语言模型的出现,不仅降低了技术门槛,还推动了全球范围内的创新与合作。本文将带你了解几款优秀的开源 AI 自然语言模型,助你在这场技术革命中抢占先机。
1. GPT-NeoX:开源巨无霸的崛起
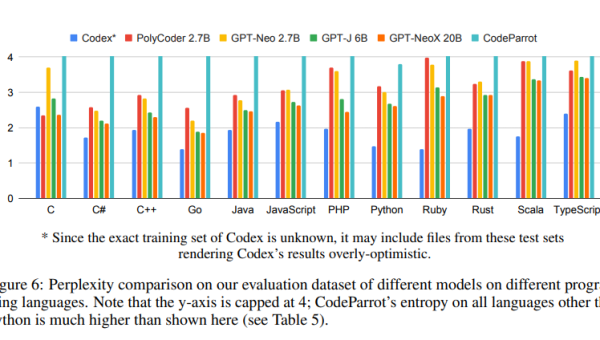
GPT-NeoX 是由 EleutherAI 团队开发的一款大规模开源语言模型。它基于 GPT-3 的架构,但通过开源的方式,让更多研究者和开发者能够参与其中。GPT-NeoX 的强大之处在于其庞大的参数量和灵活的定制能力,适合需要处理复杂语言任务的场景。
特点:
- 参数量巨大:支持数十亿级别的参数,能够处理复杂的语言任务。
- 开源社区支持:活跃的开发者社区不断优化模型性能。
- 灵活定制:用户可以根据需求调整模型结构和训练数据。
2. BLOOM:多语言模型的典范
BLOOM 是由 BigScience 项目开发的一款多语言开源模型,支持 46 种语言和 13 种编程语言。它的目标是为全球用户提供公平、透明的 AI 工具,特别适合多语言环境下的应用。
特点:
- 多语言支持:覆盖广泛的语言和编程语言,适应全球需求。
- 透明性:模型开发和训练过程完全公开,确保公平性。
- 高效性能:在多语言任务中表现出色,提升用户体验。
3. T5:文本到文本的通用模型
T5(Text-To-Text Transfer Transformer)由 Google 开发,是一款将各种 NLP 任务统一为文本到文本转换的开源模型。它的设计理念是“一切皆文本”,使得模型能够处理多种任务,如翻译、摘要、问答等。
特点:
- 任务统一:将不同 NLP 任务统一为文本转换,简化模型设计。
- 广泛适用:适用于多种语言处理任务,提升工作效率。
- 开源资源:提供丰富的预训练模型和工具,方便开发者使用。
4. BERT:革命性的预训练模型
BERT(Bidirectional Encoder Representations from Transformers)由 Google 开发,是一款革命性的预训练语言模型。它通过双向编码器捕捉上下文信息,显著提升了多项 NLP 任务的性能。
特点:
- 双向编码:捕捉上下文信息,提升模型理解能力。
- 广泛适用:在问答、情感分析等任务中表现优异。
- 开源资源:提供多种预训练模型,方便开发者快速上手。
5. XLNet:超越 BERT 的新星
XLNet 是由 CMU 和 Google 联合开发的一款开源模型,结合了自回归和自编码模型的优点。它在多项 NLP 任务中超越了 BERT,成为新一代的标杆。
特点:
- 自回归与自编码结合:提升模型性能,适应复杂任务。
- 广泛适用:在问答、文本生成等任务中表现优异。
- 开源资源:提供多种预训练模型,方便开发者使用。
结语
开源 AI 自然语言模型的发展,不仅推动了技术的进步,还为全球开发者提供了丰富的工具和资源。无论是 GPT-NeoX 的庞大参数量,还是 BLOOM 的多语言支持,这些模型都在各自的领域展现出了强大的潜力。希望本文的推荐能帮助你在 AI 的海洋中找到适合自己的工具,共同探索未来的无限可能。
通过深入了解这些开源模型,你将能够更好地应对复杂的语言处理任务,提升工作效率,甚至在 AI 领域实现自己的创新。让我们一起拥抱这场技术革命,开创更加智能的未来。
















暂无评论内容